
一、简介
- 只需提供一个视频主题或关键词,就可以全自动生成视频文案、视频素材、视频字幕、视频背景音乐,然后合成一个高清的短视频
- 主要逻辑:输入视频主题 => 大语言模型生成视频文案、关键词 =>拿关键词去Pexels资源平台拉取素材数据 => 视频素材拼接、文案字幕生成、字幕配音 => 合成结果视频
- 计算资源要求不高,没有GPU也可以,普通电脑就能运行
- 开源项目地址:https://github.com/harry0703/MoneyPrinterTurbo
二、安装(Docker示例)
- 提前准备好docker、docker-compose环境
- 新建docker-compose.yml,配置内容如下:
services: webui: image: ghcr.io/luler/money_printer_turbo_docker:latest container_name: "webui" ports: - "8501:8501" command: [ "streamlit", "run", "./webui/Main.py","--browser.serverAddress=127.0.0.1","--server.enableCORS=True","--browser.gatherUsageStats=False" ] volumes: - ./config.toml:/MoneyPrinterTurbo/config.toml - ./storage:/MoneyPrinterTurbo/storage restart: always api: image: ghcr.io/luler/money_printer_turbo_docker:latest container_name: "api" ports: - "8080:8080" command: [ "python3", "main.py" ] volumes: - ./config.toml:/MoneyPrinterTurbo/config.toml - ./storage:/MoneyPrinterTurbo/storage restart: always - 相同目录下,下载文件:https://raw.githubusercontent.com/harry0703/MoneyPrinterTurbo/main/config.example.toml,命名为 config.toml,编辑 config.toml 文件,配置 pexels_api_keys 和 llm_provider,其中pexels_api_keys可以注册登录https://www.pexels.com/api/获得,模型的选择openai兼容或者配置其他模型,如下(部分配置):
video_source = "pexels" #这里填写你的pexels api key pexels_api_keys = [ "xxxxxxx"] #此处省略其他配置...... llm_provider="openai" #这里填写你的openai api key openai_api_key = "sk-xxxxxx" #openai请求路径 openai_base_url = "https://api.openai.com/v1" #openai模型名称 openai_model_name = "gpt-4o" #此处省略其他配置...... - 配置完上面的内容,就可以直接启动了
docker-compose up -d
三、使用
访问页面:http://127.0.0.1:8501/ ,默认是英文的,可以配置成简体中文
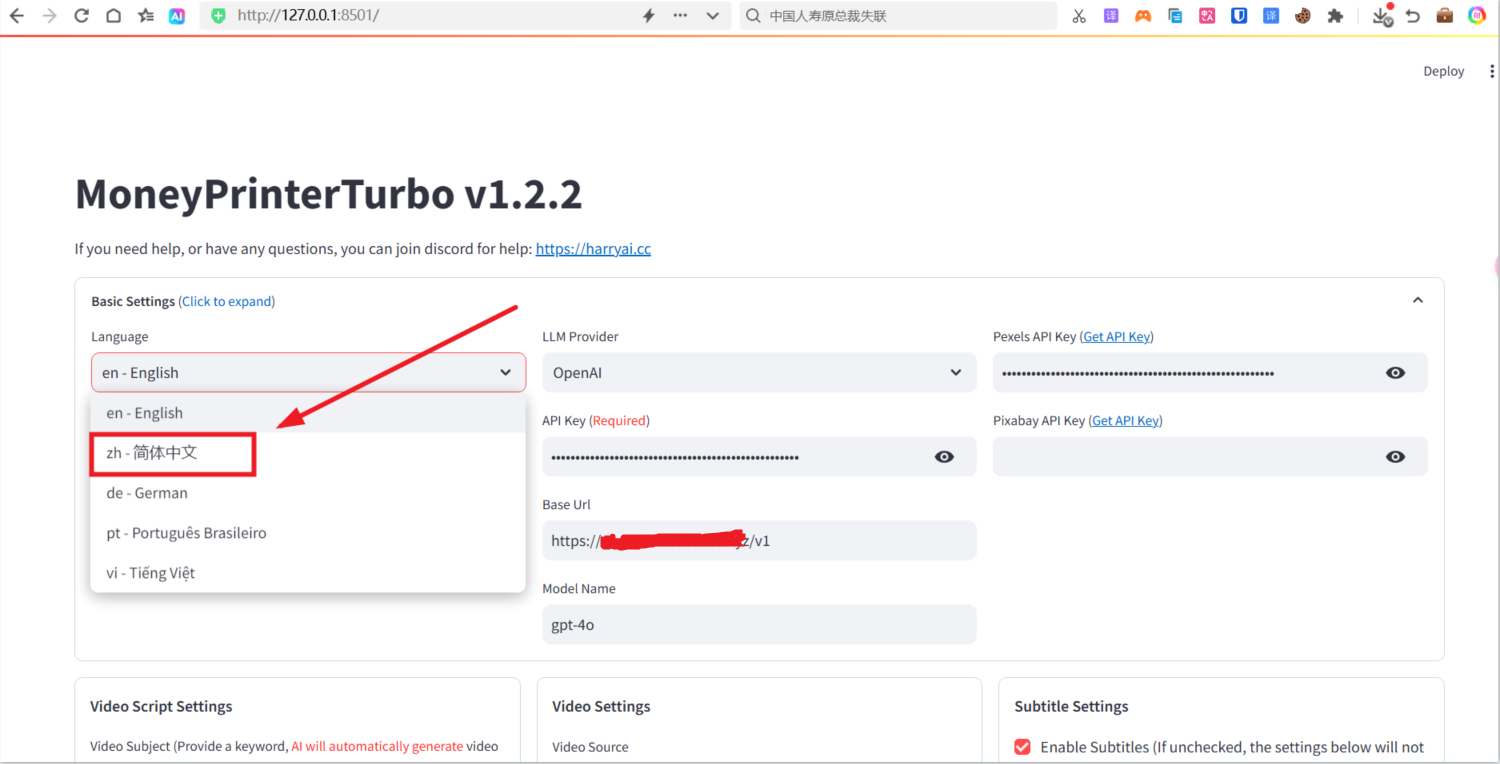
输入视频主题,开始生成目标视频
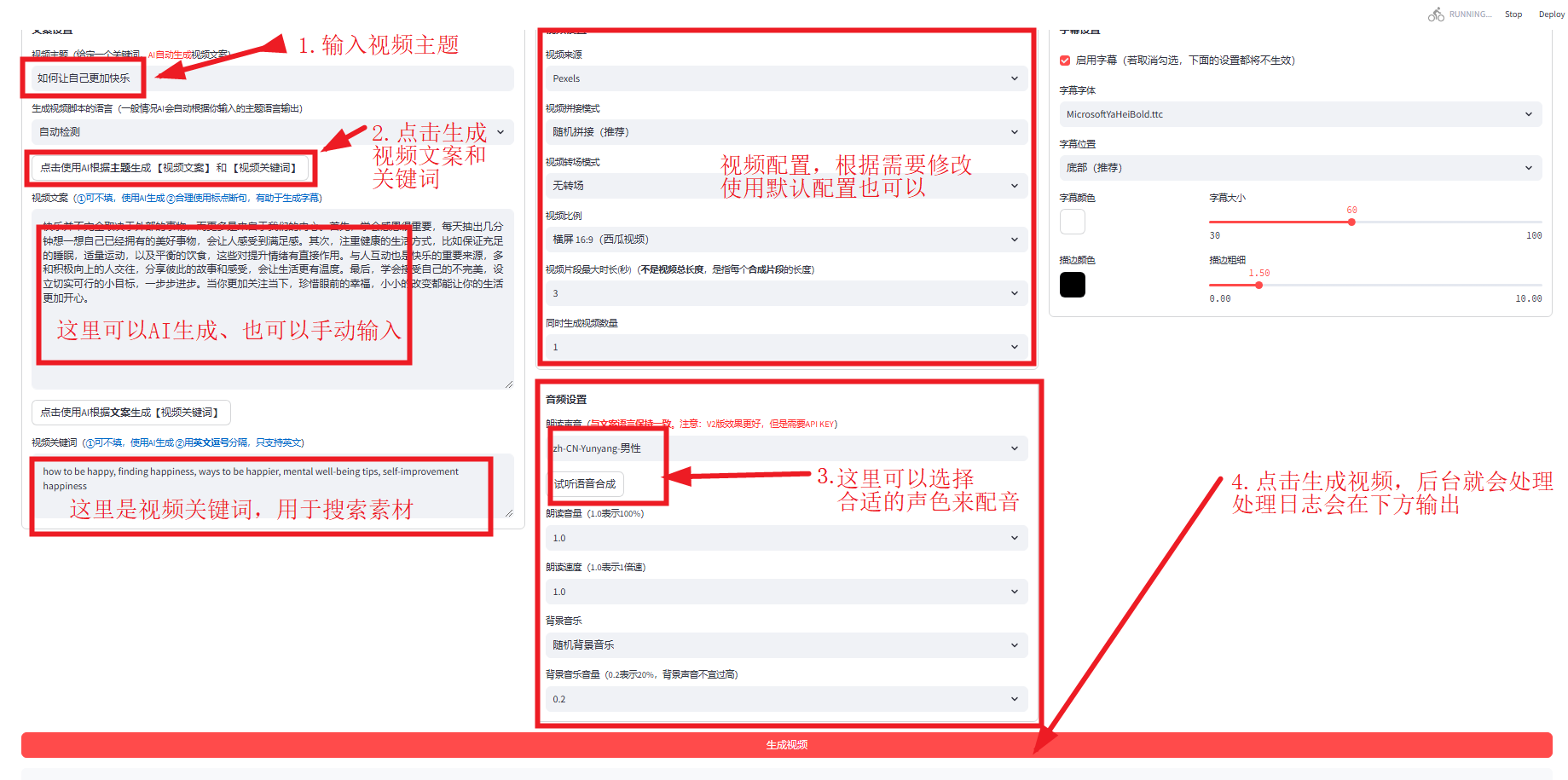
生成的示例视频
四、总结
- 非常方便和智能,只需要输入视频主题,其他都可以让AI和程序自动去处理
- 视频素材都是从pexels下载的免费使用的高清视频,合成的视频质量很高
- 可以自定义调整文案、关键词、音频视频属性等,可用性可玩性很高
评论
发表评论